How Pluto Works
这篇文档将介绍 Pluto 的工作原理。
用户工作流
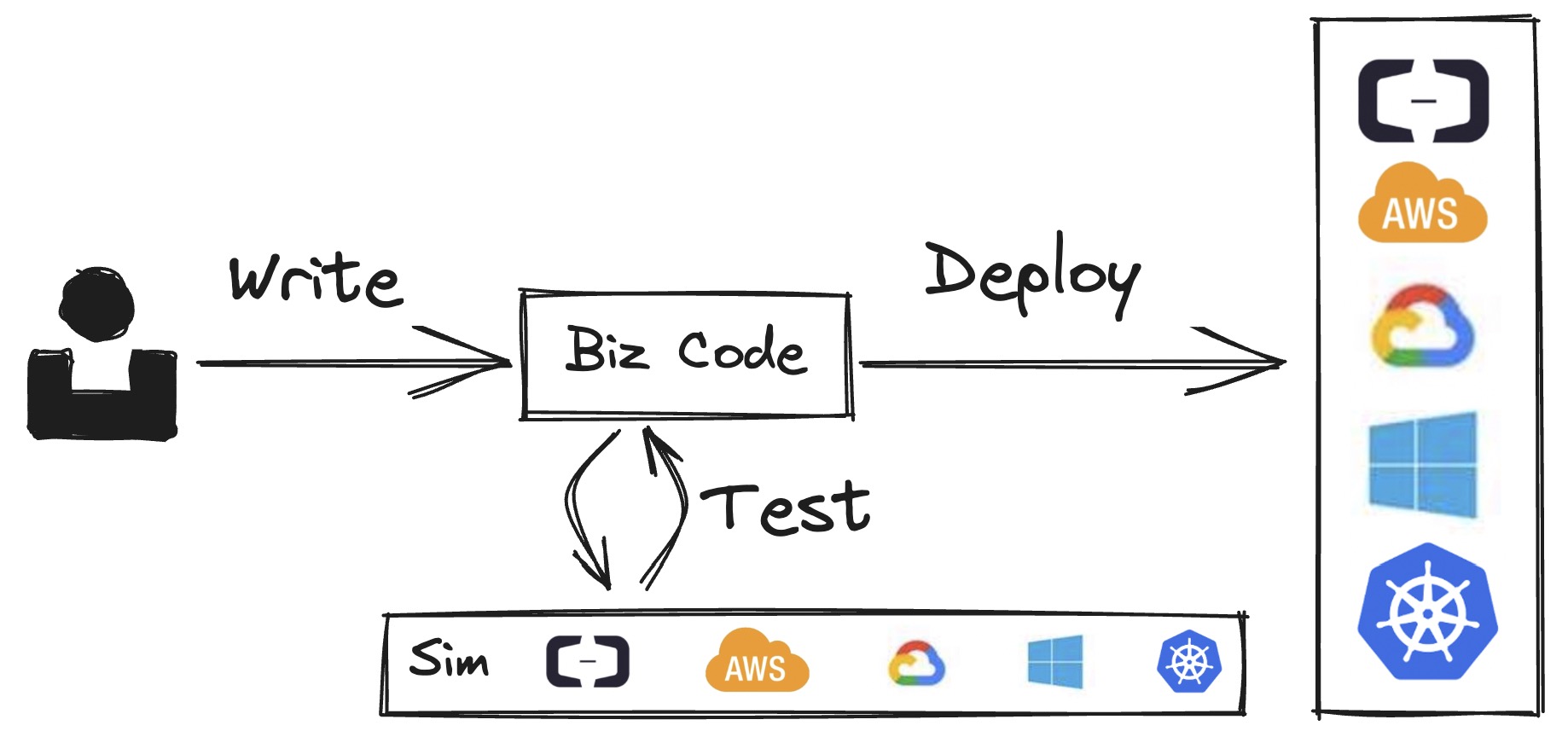
Write - Test - Deploy 是 Pluto 提供给用户的工作流。
Write 阶段,用户依赖 SDK 进行开发应用程序,代码中,用户定义其所需的资源变量。
Test 阶段,Pluto 提供在模拟环境和真实环境进行单元测试的能力,用户根据研发阶段进行选择。在真实环境测试,可以保证测试环境与线上环境一致,在上线前发现执行环境可能带来的问题。在模拟环境测试,可以避免真实环境测试发布流程带来的时间开销,在本地快速验证业务逻辑的正确性。
Deploy 阶段,用户指定要部署的云平台,由 Pluto 自动化完成从代码到运行时的全部过程。
引擎工作流
那么,Pluto 是如何将用户代码一步步部署到运行时的呢?下面这张图概括了 Pluto 的整体工作流程。
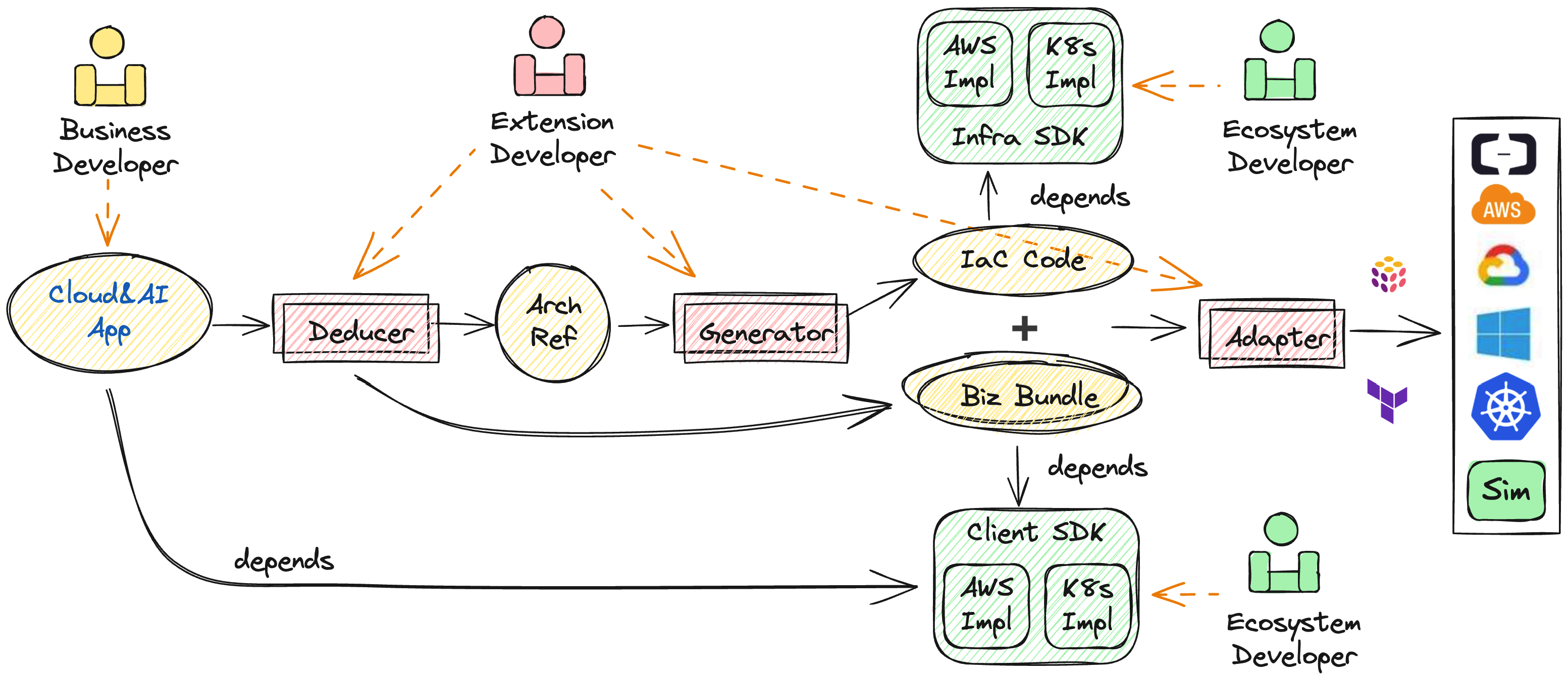
Pluto 的整体工作流程包括推导、生成、部署三个阶段,每个阶段的功能组件分别称作推导器、生成器、适配器,推导器与生成器可以根据需要进行扩展替换。
用户提交代码后,首先,推导器从用户代码中推导出所需云资源及资源间依赖关系,构建云参考架构(architecture reference)。然后,生成器依据 arch ref 生成一份独立于用户代码的 IaC 代码,并将用户代码拆分成多个业务模块。最终,由适配器根据 IaC 代码的类型调用相应 IaC 引擎执行部署,将应用程序发布到指定的云平台上。
推导阶段
推导阶段的主要目的是从用户代码中推导出应用程序对基础设施资源的依赖,以及确定应用程序在云平台上的参考架构。推导器的实现方式不做限制,只要实现相应接口,能完成此目的即可。
基于静态程序分析的推导器
Pluto 仓库中提供了基于静态程序分析的推导器 (opens in a new tab)实现。该推导器主要是结合 API SDK 来推导资源依赖,以及构建参考架构。
该推导器判断基础设施资源依赖的方式是:用户编写的代码中会定义资源变量,如 const queue = new Queue();,而资源变量的类型定义则来自依赖的 SDK,该类型在实现上实现了 Resource 接口。静态分析器会通过变量类型是否是 Resource 的实例对象,进而判断是否是基础设施资源类型。
通过分析变量之间的调用关系,推导器可以进一步推导生成基础设施资源之间的关系。例如,当调用 queue.subscribe(fn) 时,方法中的函数参数 fn 即为 queue 的订阅处理过程。这意味着在进行基础设施部署时,我们需要将该函数部署为一个计算组件(例如 Lambda 函数),并设置该组件与队列相关的触发条件。而当调用 queue.push 时,表示调用该方法的函数在运行时会使用 queue 这个基础设施资源。通过以上方式可以分析基础设施资源在部署时的依赖关系,与运行时的调用关系。
通过以上手段,可以分析出应用程序依赖的全部基础设施资源,以及资源间的关系,构建云参考架构。
生成阶段
生成阶段的主要目的是依据参考架构生成一份 IaC 代码,同时对用户代码进行拆分、转换、编译等操作。与推导器一样,对生成器的实现方式不做限制,只需要实现相应接口即可。
基于 IaC SDK 的生成器
Pluto 仓库中提供了一个基于 IaC SDK 的生成器 (opens in a new tab)实现。该生成器利用 IaC SDK 定义基础设施资源,并将用户代码拆分为多个 Lambda 函数模块。
API SDK 有一个与之配套的 IaC SDK,用于为 API SDK 定义的每个资源类型提供在不同平台上的 IaC 实现。生成器会根据参考架构生成每个资源变量对应的 IaC 类型实例对象,并配置 IaC 对象之间的访问权限等依赖关系。
此外,生成器还会根据参考架构中对计算模块的划分,将用户代码拆分成多个代码文件,每个文件都是一个可导入的计算模块。
最终,所有代码将被编译。
部署阶段
最终,Pluto 根据生成的 IaC 代码类型,调用相应适配器,由适配器调用相应 IaC 引擎执行 IaC 代码,完成基础设施资源的创建,与应用程序计算模块的发布。
在执行 IaC 代码过程中,会对代码进行封装打包等操作,使其适配各云平台的发布规则。